library(sidrar) #baixar dados IBGE
library(janitor) #limpeza dos dados
library(dplyr) #manipulação dos dados
library(stringr) #trabalhar com strings/texto
library(ggplot2) #gráficosDecifrando gráficos #2
tutorial
dataviz
ggplot2
Do Jornal para o R

Como isso foi feito?
Todo dia vemos gráficos nos jornais, mas nem sempre sabemos como eles foram feitos. De onde vieram os dados? Como foram tratados? E será que dá para recriá-los usando o R?
Nesta série, pegamos gráficos publicados nos principais jornais e recriamos do zero usando R, tidyverse e ggplot2. Vou mostrar como encontrar os dados, organizá-los e gerar visualizações que chegam o mais próximo possível do original – tudo de forma transparente e didática. Sim! Vamos fazer e aprender juntos!
E tem mais: todo o código e dados utilizados estarão disponíveis e comentados (clique nos números abaixo de cada conjunto de código!). E por estarmos trabalhando com uma linguagem de programação, todos vão obter o mesmo resultado ao final do script.
Acompanhe a série e veja como transformar dados brutos em visualizações incríveis!
Post anterior
Quer ver o post anterior? Acesse abaixo
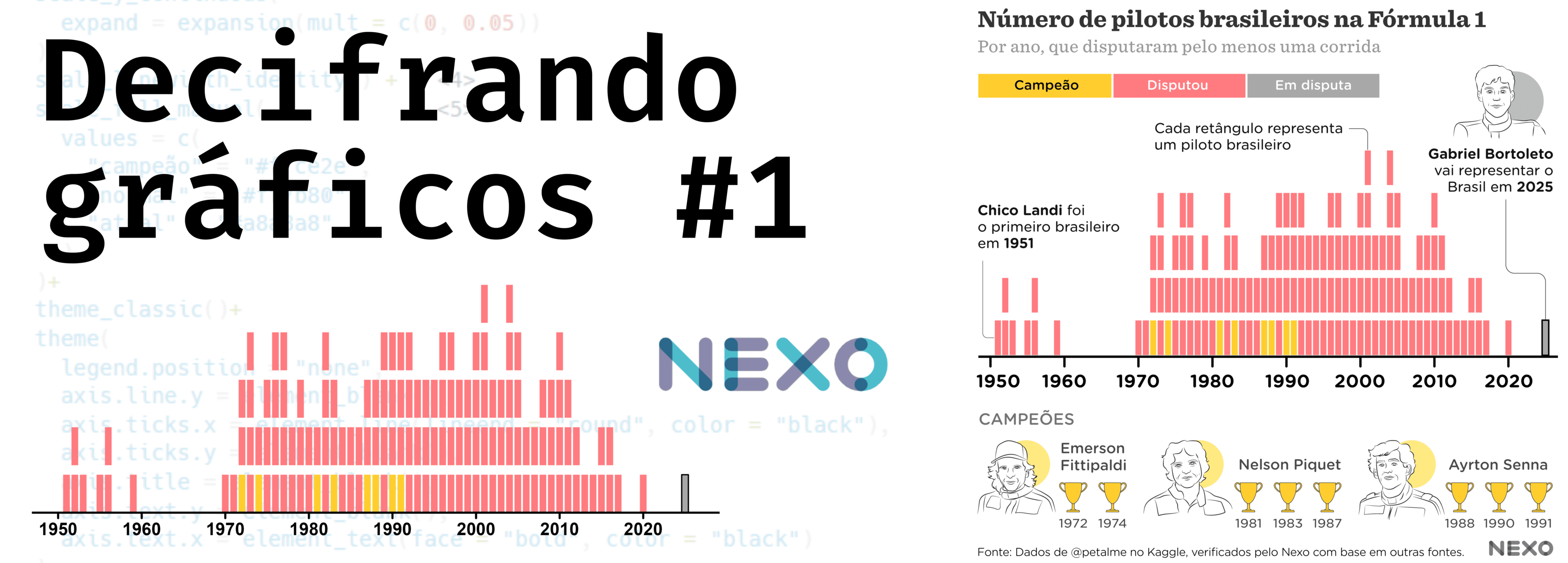
#2 - Pirâmide etária indígena (Folha de São Paulo)
Dessa vez vamos analisar um gráfico publicado pela Folha de São Paulo com dados do Censo 2022: População indígena cresce no Norte, mas envelhece ao redor das cidades

Eu particularmente acho muito legal visualizar pirâmides etárias, como essa que fiz com o pessoal da Base dos Dados. Vamos fazer apenas o gráfico, já que as anotações geralmente são adicionadas na pós produção (p. ex. Illustrator) e deixaria este post muito extenso.
Obtendo os dados
Todos os dados do Censo 2022 estão disponíveis na aba de Downloads do portal: https://censo2022.ibge.gov.br/panorama/downloads.html. Lá vamos acessar os resultados Quilombolas e Indígenas, por sexo e idade, segundo recortes territoriais específicos - Resultados do universo e então selecionamos População indígena, por localização do domicílio, grupos de idade e sexo.
Logo nessa página vemos que os dados estão disponíveis através do SIDRA (Sistema IBGE de Recuperação Automática), que é basicamente uma plataforma que concentra todos os dados do IBGE! E o melhor: podemos acessar diretamente do R com o pacote {sidrar}!
Antes de tudo, vamos carregar os pacotes necessários
Agora só precisamos do número da tabela disponível no site (que é 8175) e rodar o código abaixo:
#install.packages("sidrar")
library(sidrar)
pop_ind <- sidrar::get_sidra(8175)Pronto, fácil assim já temos os dados do Censo para este gráfico!
Trabalhando com os dados
Pois é, nossos dados sempre têm os nomes das variáveis com letras maiúsculas, espaços e acentos. Vamos padronizar para snake_casecom o pacote {janitor} e também selecionar apenas as variáveis necessárias para este gráfico. Vamos salvando cada passo em um novo objeto para ficar mais fácil de acompanhar.
pop_ind2 <- pop_ind |>
janitor::clean_names() |>
dplyr::select(
variavel,
ano,
idade,
sexo,
localizacao_do_domicilio,
valor
)Mas veja que temos um valor Total em idade, sexo e localizacao_do_domicilio. Não vamos precisar dos totais, então podemos removê-los.
pop_ind3 <- pop_ind2 |>
dplyr::filter(
idade != "Total",
sexo != "Total",
localizacao_do_domicilio != "Total"
)Nessa tabela, temos as idades individuais, ou agrupadas a cada 5 anos. Vamos selecionar apenas as linhas com as idades agrupadas.
pop_ind4 <- pop_ind3 |>
filter(
idade %in% c(
"0 a 4 anos",
"5 a 9 anos",
"10 a 14 anos",
"15 a 19 anos",
"20 a 24 anos",
"25 a 29 anos",
"30 a 34 anos",
"35 a 39 anos",
"40 a 44 anos",
"45 a 49 anos",
"50 a 54 anos",
"55 a 59 anos",
"60 a 64 anos",
"65 a 69 anos",
"70 a 74 anos",
"75 a 79 anos",
"80 a 84 anos",
"85 a 89 anos",
"90 a 94 anos",
"95 a 99 anos",
"100 anos ou mais"
)
)
Preguiça de escrever tudo
Se você não quer ficar digitando tudo (ou não quer pedir para o chatGPT escrever para você), é possível selecionar as linhas usando expressões regulares! Sim, elas parecem bruxaria, mas tem uma colinha que ajuda muito!
O segredo é encontrar padrões! Veja que as categorias são basicamente número+ a +número, e o “100 anos ou mais” colocamos na mão. Vamos lá!
pop_ind4 <- pop_ind3 |>
filter(
1 stringr::str_detect(
2 idade,
3 "[:digit:] a [:digit:]|100 anos ou mais")
)- 1
- Detecta a ocorrência de expressões regulares
- 2
-
Na variável
idade - 3
- E a expressão é: [número] a [número] OU “100 anos ou mais”
Bem mais simples!
Agora para deixar igualzinho ao gráfico, vamos remover as palavras ” anos” e transformar “100 anos ou mais” em “100+”
pop_ind5 <- pop_ind4 |>
mutate(
1 idade2 = stringr::str_remove(
2 idade,
3 " anos.*"
),
4 idade2 = ifelse(idade2 == 100, "100+", idade2)
)- 1
- Remove a ocorrência de expressões regulares.
- 2
-
Na variável
idade. - 3
- E a expressão é: [espaço]anos(e tudo que vier depois).
- 4
-
Se
idade2for igual a 100, transformar em “100+”, caso contrário, mantenha como está.
Ótimo, já temos a variável pronta, vamos calcular as proporções agrupadas pela localização do domicílio.
pop_ind6 <- pop_ind5 |>
1 group_by(localizacao_do_domicilio) |>
2 add_count(name = "total", wt = valor) |>
3 ungroup() |>
4 mutate(prop = valor / total)- 1
- Agrupamos os dados pela variável localizacao_do_domicilio.
- 2
- Criamos uma nova coluna chamada total com a soma ponderada de valor dentro de cada grupo.
- 3
-
Retiramos o agrupamento com
ungroup()para evitar efeitos indesejados nas próximas operações. - 4
- Calculamos a proporção de cada linha dentro do grupo, dividindo valor pelo total correspondente.
Agora vamos fazer um truque e multiplicar os prop para homens por -1, assim eles ficam do lado esquerdo da pirâmide.
pop_ind7 <- pop_ind6 |>
mutate(
1 prop = ifelse(sexo == "Homens", prop*-1, prop)
)- 1
- Inverte o sinal da proporção para homens, para que apareçam do lado esquerdo da pirâmide.
Vamos ver se os dados estão prontos?
- 1
- Mapeia a proporção no eixo x, idade no eixo y e cor por sexo.
- 2
-
Cria as barras da pirâmide populacional com
geom_col().

Veja que as categorias de idade estão seguindo uma ordem alfabética, mas queremos que sigam a ordem da pirâmide etária. Vamos ordenar a variável idade2 de acordo com a ordem que queremos. Para isso vamos transformar ela em um fator usando a função fct_inorder() do pacote {forcats} (é um anagrama para factors!)
pop_ind8 <- pop_ind7 |>
1 mutate(idade2 = forcats::fct_inorder(idade2))- 1
-
Converte a variável
idade2em fator e preserva a ordem atual dos valores, garantindo que as faixas etárias apareçam na ordem do dataset no gráfico.
Agora tudo está ordenado!
pop_ind8 |>
ggplot(aes(x = prop, y = idade2, fill = sexo))+
geom_col()
Pronto! Temos os dados prontos para o gráfico! Agora vamos para a parte mais legal!
Criando o gráfico
Primeiro vamos dividir os dados em dois grupos: os que estão dentro das terras indígenas e os que estão fora. Para isso, vamos usar a função filter() dentro de cada geometria do geom_col().
Lembre-se que o grupo “Em terras indígenas” deve ser um retângulo preenchido e o grupo “Fora de terras indígenas” deve ser apenas contornado. Para isso, vamos usar o argumento fill = NA para criar uma geometria apenas com o contorno. Como o contorno está da mesma cor do preenchimento, vamos usar o color = "black" apenas para visualizar.
pop_ind8 |>
ggplot(aes(x = prop, y = idade2,
fill = sexo))+
geom_col(
data = ~filter(.,
1 localizacao_do_domicilio == "Em terras indígenas"),
2 color = NA
)+
geom_col(
data = ~filter(.,
3 localizacao_do_domicilio == "Fora de terras indígenas"),
fill = NA,
4 color = "black"
)- 1
-
Usa
filter()para manter só as observações dentro das terras indígenas. - 2
- Retira o contorno das barras preenchidas.
- 3
-
Usa
filter()para manter só as observações fora das terras indígenas. - 4
- Define a cor do contorno como preta, apenas para fins de visualização.

Faltam as cores! Vamos utilizar o argumento color também. E definir as cores utilizando scale_color_manual() e scale_fill_manual().
pop_ind8 |>
ggplot(aes(x = prop, y = idade2,
fill = sexo, color = sexo))+
geom_col(
data = ~filter(.,
localizacao_do_domicilio == "Em terras indígenas"),
color = NA)+
geom_col(
data = ~filter(.,
localizacao_do_domicilio == "Fora de terras indígenas"),
fill = NA)+
1 scale_color_manual(
values = c(
"Mulheres" = "#420e44",
"Homens" = "#076e56"
)
)+
2 scale_fill_manual(
values = c(
"Mulheres" = "#b3abce",
"Homens" = "#a5d4cf"
)
)- 1
-
Define as cores do contorno (
color) para cada sexo. - 2
-
Define cores mais claras de preenchimento (
fill) para cada sexo.

Agora o gráfico já está quase igual! Só precisamos mexer no Tema com a função theme(). Vamos deixar o fundo branco, tirar as grades, deixar os eixos mais bonitos e remover as legendas.
pop_ind8 |>
ggplot(aes(x = prop, y = idade2,
fill = sexo,
color = sexo))+
geom_col(
data = ~filter(.x,
localizacao_do_domicilio == "Em terras indígenas"),
color = NA)+
geom_col(
data = ~filter(.x,
localizacao_do_domicilio == "Fora de terras indígenas"),
fill = NA)+
1 scale_x_continuous(
breaks = seq(-0.08,0.08,0.02),
labels = c("8%","6","4","2","0","2","4","6","8%")
)+
scale_fill_manual(
values = c(
"Mulheres" = "#b3abce",
"Homens" = "#a5d4cf"
)
)+
scale_color_manual(
values = c(
"Mulheres" = "#420e44",
"Homens" = "#076e56"
)
)+
2 theme_minimal()+
3 theme(
legend.position = "none", #sem legenda
plot.background = element_rect(fill = "white", color = NA), #adiciona fundo
panel.grid.major.x = element_blank(), #sem grade major
panel.grid.minor.x = element_blank(), #sem grade minor
axis.title = element_blank(), #sem título dos eixos
axis.text = element_text(color = "black"), #texto em preto
axis.ticks.x = element_line(color = "#ebebeb") #ticks em cinza
)+
4 coord_cartesian(
xlim = c(-0.08,0.08)
)- 1
- Define as quebras do eixo x (de -0.08 até 0.08 a cada 0.02 já que são porcentagens) e ajusta os rótulos para mostrar proporções negativas e positivas como porcentagens igual ao gráfico original.
- 2
-
Usa um tema claro e limpo (
theme_minimal()) parecido, como base para o gráfico. - 3
- Remove legenda, grades do eixo x, títulos dos eixos e ajusta o estilo dos textos e ticks para deixar igual ao original.
- 4
- Ajusta manualmente os limites do eixo x para que o gráfico termine simetricamente em -8% e 8%.

Conseguimos! Até que ficou bem parecido!
Espero que este post tenha sido útil para você! Se tiver alguma dúvida, sugestão (qual será o próximo post?) ou crítica, mande um e-mail!
Quer conhecer mais o meu trabalho? Veja meu Portfólio!